Use AWS SES to receive and parse emails
2. Steps
2.1. create an identity for a domain or subdomain
You cannot use an existing email address because that would imply it's already managed by some other email service.
This domain/subdomain identity will be able to act as domain for a new email address to be managed by AWS SES.
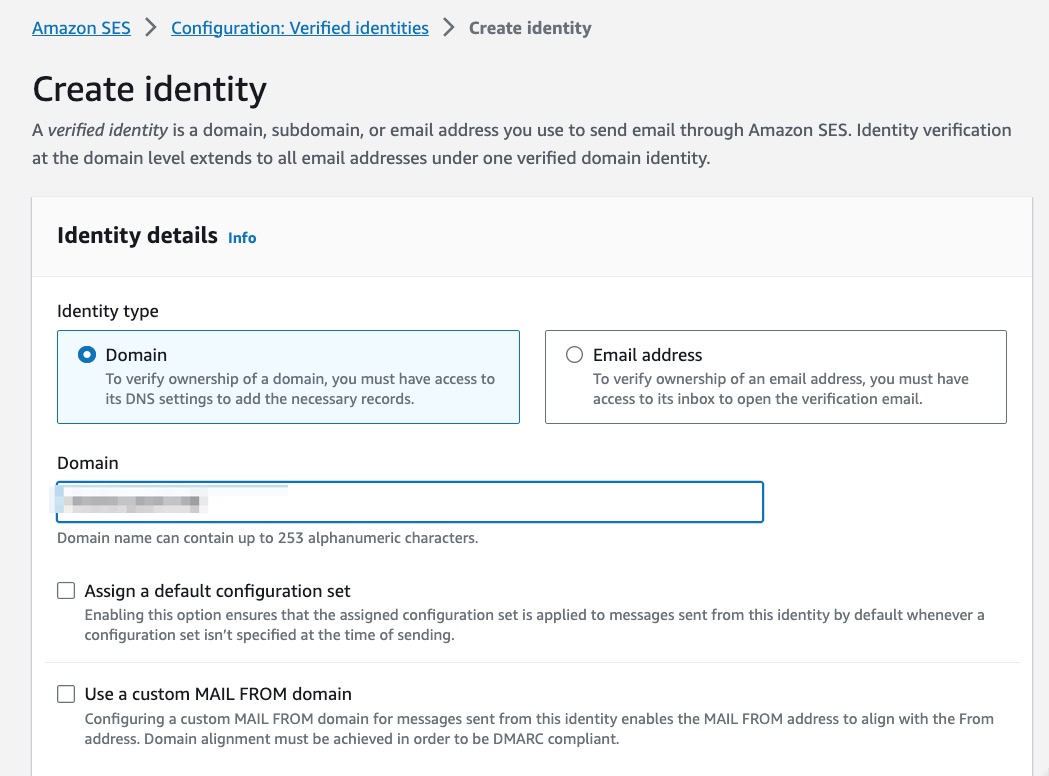
Because my domain is managed by Route53, I only need to fill in the domain I want to use and continue. Wait for a couple of minutes and it will automatically verify the [BROKEN LINK: CD627649-6E9F-46EB-AE68-5FB8F43B994E] settings.
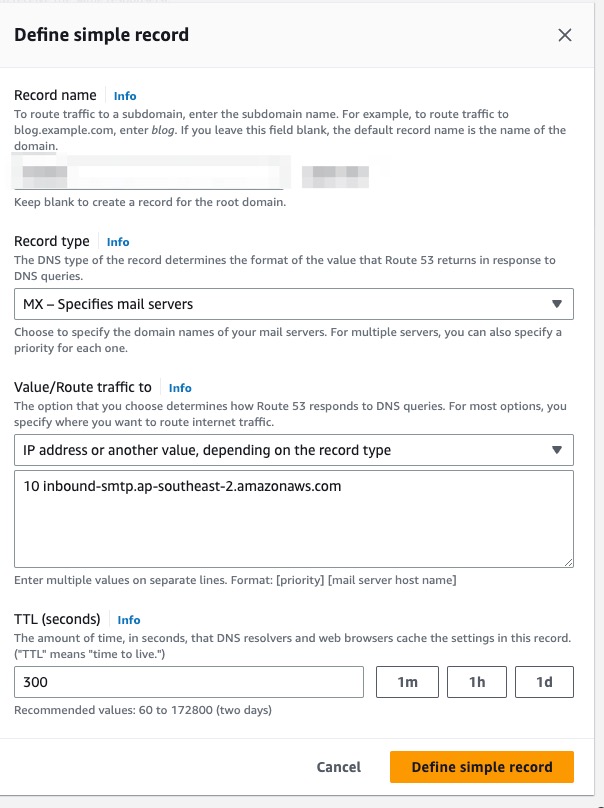
2.2. Publishing an MX record for Amazon SES email receiving
Get the SES endpoint for receiving the email. In my case it's: inbound-smtp.ap-southeast-2.amazonaws.com
.
Create an [BROKEN LINK: CB40B160-9D7A-4BEC-BD85-F409B72E6F68] record. Record name should be your domain/subdomain.
2.3. Giving permissions to Amazon SES for email receiving
Attach the following policy to the AWS S3 bucket you want to put the emails in.
{ "Version":"2012-10-17", "Statement":[ { "Sid":"AllowSESPuts", "Effect":"Allow", "Principal":{ "Service":"ses.amazonaws.com" }, "Action":"s3:PutObject", "Resource":"arn:aws:s3:::bucket-name/*", "Condition":{ "StringEquals":{ "AWS:SourceAccount":"account-number", "AWS:SourceArn": "arn:aws:ses:ap-southeast-2:account-number:receipt-rule-set/tax-invoices:receipt-rule/forward-attachment" } } } ] }
2.4. Add lambda function to process the attachment
sample event
{"Records": [{"eventVersion": "2.1", "eventSource": "aws:s3", "awsRegion": "ap-southeast-2", "eventTime": "2023-10-05T04:57:40.171Z", "eventName": "ObjectCreated:Put", "userIdentity": {"principalId": "AWS:ZXC2IU3VLCK5RY5:a41bc866759cc95c7330a"}, "requestParameters": {"sourceIPAddress": "101.0.4.6"}, "responseElements": {"x-amz-request-id": "6TS8WGRDNT4T3P5T", "x-amz-id-2": "4RuZDptjBdMxsC3"}, "s3": {"s3SchemaVersion": "1.0", "configurationId": "7b22853", "bucket": {"name": "bucket-name", "ownerIdentity": {"principalId": "8Z"}, "arn": "arn:aws:s3:::bucket-name"}, "object": {"key": "email/tax/82ghepkvblmfnh81", "size": "285170", "eTag": "cb607b6f486ae754444e", "sequencer": "41F793986"}}}]}
from email.message import MIMEPart import email import zipfile import os import gzip import string import boto3 import urllib import email.utils print('Loading function') s3 = boto3.client('s3') s3r = boto3.resource('s3') tmp_dir = "/tmp/output/" output_bucket = "bucket-name" TAX_INVOICE_MAILBOX = 'tax-stuff@domain' PRIVATE_INVOICE_MAILBOX = 'private-stuff@domain' def get_mailbox(msg): mailbox = email.utils.parseaddr(msg.get("To"))[1] return mailbox def extract_attachment(attachment, attachment_name): file_path = tmp_dir + attachment_name open(file_path, 'wb').write(attachment.get_payload(decode=True)) return file_path def upload_resulting_files_to_s3( mailbox, file_path, msg_date, file_name_custom_prefix="" ): # Put all XML back into S3 (Covers non-compliant cases if a ZIP contains multiple results) print("Uploading: " + file_path) # File name to upload file_name = file_path.split('/')[-1] if len(file_name_custom_prefix) > 0: file_name = f"{}-{}" output_prefix = f"invoice" if mailbox == TAX_INVOICE_MAILBOX: output_prefix = f'{}/tax' else: output_prefix = f'{}/private' output_prefix = f"{}/{}/{}" s3r.meta.client.upload_file( file_path, output_bucket, f"{}/{}" ) def get_attachment_name(msg): attachment_name = "default_name" if msg.is_multipart(): for part in msg.walk(): content_disposition = part.get("Content-Disposition", "") if content_disposition.startswith("attachment"): attachment_name = part.get_filename() elif content_disposition.startswith("inline"): attachment_name = part.get_filename() # additional handling for inline attachments if needed else: # handle other content types if needed pass else: # handle single part email if needed pass return attachment_name # Delete the file in the current bucket def delete_file(key, bucket): s3.delete_object(Bucket=bucket, Key=key) print("%s deleted fom %s ") % (key, bucket) def lambda_handler(event, context): bucket = event['Records'][0]['s3']['bucket']['name'] key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key']) print(f"bucket: {}") try: response = s3r.Bucket(bucket).Object(key) # Read the raw text file into a Email Object raw_msg = response.get()["Body"].read().decode("utf-8") mime_msg = email.message_from_string(raw_msg, _class=MIMEPart) plain_msg = email.message_from_string(raw_msg) file_name_custom_prefix = "" for p in plain_msg.walk(): if p.get_content_type() == "text/plain": if "!!!" in p.get_payload(): file_name_custom_prefix = ( p.get_payload().split("\\n")[0].split("\n")[0].strip() ) file_name_custom_prefix = file_name_custom_prefix.replace("!", "") print(f"prefix: {}") msg_date = email.utils.parsedate_to_datetime(mime_msg.get("Date")) print("Message Date:", msg_date) # Create directory for XML files (makes debugging easier) if os.path.isdir(tmp_dir) == False: os.mkdir(tmp_dir) for attachment in mime_msg.iter_attachments(): # The first attachment # attachment = msg.get_payload()[0] print(attachment.get_content_type()) # Extract the attachment into /tmp/output file_path = extract_attachment(attachment, get_attachment_name(mime_msg)) # Upload the XML files to S3 upload_resulting_files_to_s3( get_mailbox(mime_msg), file_path, msg_date, file_name_custom_prefix, ) return 0 except Exception as e: print(e) print( 'Error getting object {} from bucket {}. Make sure they exist ' 'and your bucket is in the same region as this ' 'function.'.format(key, bucket) ) raise e # delete_file(key, bucket)
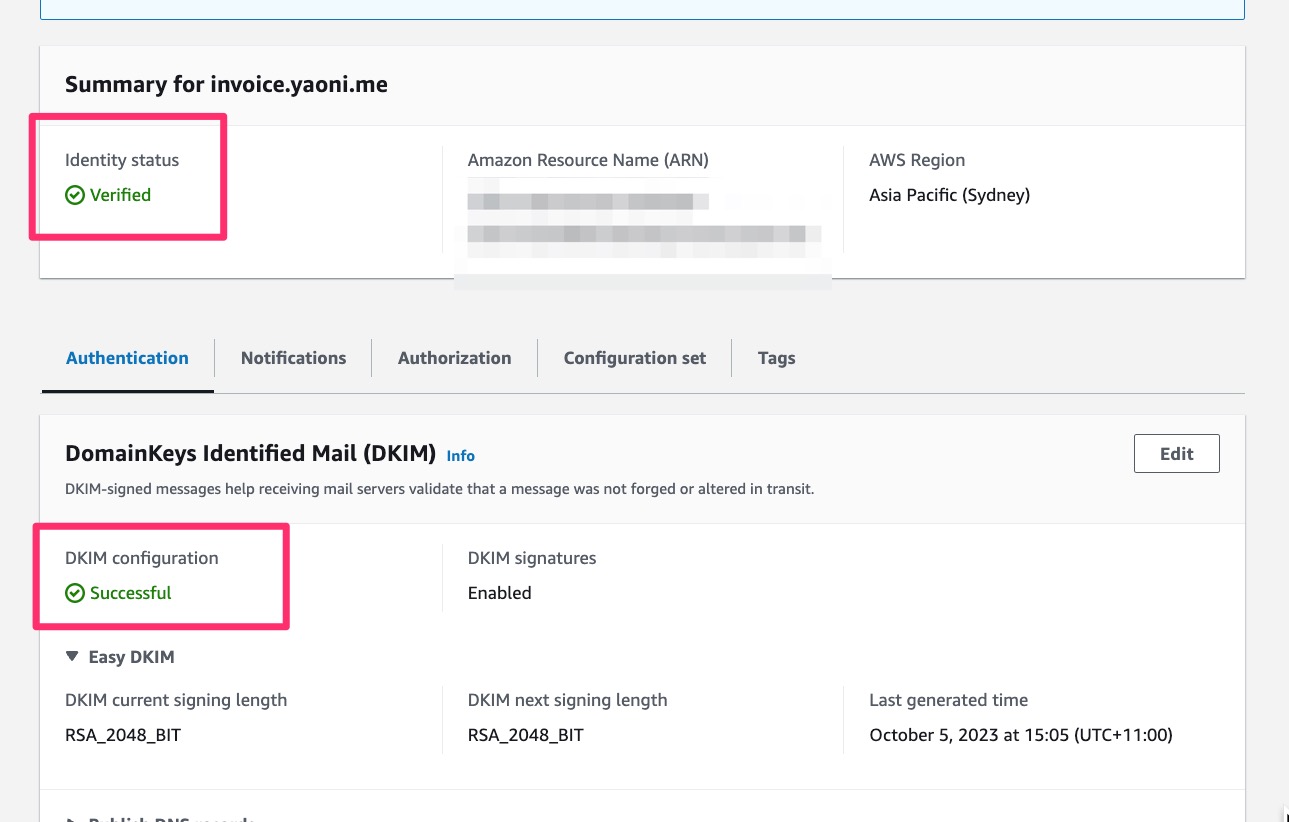
2.5. Remember to verify DKIM
As of Jan 2024 the above steps didn't work for one of my email receiving domains because I moved my domain's Name Servers to Cloudflare.
I was receiving this error:
550 5.1.1 Requested action not taken: mailbox unavailable
Basically it means the server couldn't be found.
Eventually I figured out that SES email receiving domain needed DKIM signing/verification.
Grabbed the required records from SES console and added them in [BROKEN LINK: FC780D1D-2F80-4CDC-B4F8-038A2161E7E8] and it's all good.
